A user clicks Approve refund. The button disables. A success toast appears. The page refreshes and the refund row shows Processing.
Every visible part of the product says the action worked.
But nothing happened.
The frontend emitted an event with the wrong payload shape. The backend accepted it because the request was syntactically valid. The auth layer stripped a claim needed by the refund worker. A queue message was published without the merchant context. The worker retried twice, then dead-lettered. The webhook to the payment processor never fired. Finance never got the approval task. The customer support agent moved on because the UI looked done.
The tests were green.
This is the failure pattern more teams are running into as AI writes a larger share of product code. Agent-written pull requests are often competent at local correctness. They update a component. They add an endpoint. They patch a serializer. They satisfy type checks. They regenerate fixtures. They make the UI test pass. Sometimes they even improve unit coverage.
And still the change fails in production, not because the code is obviously broken, but because the handoff is broken.
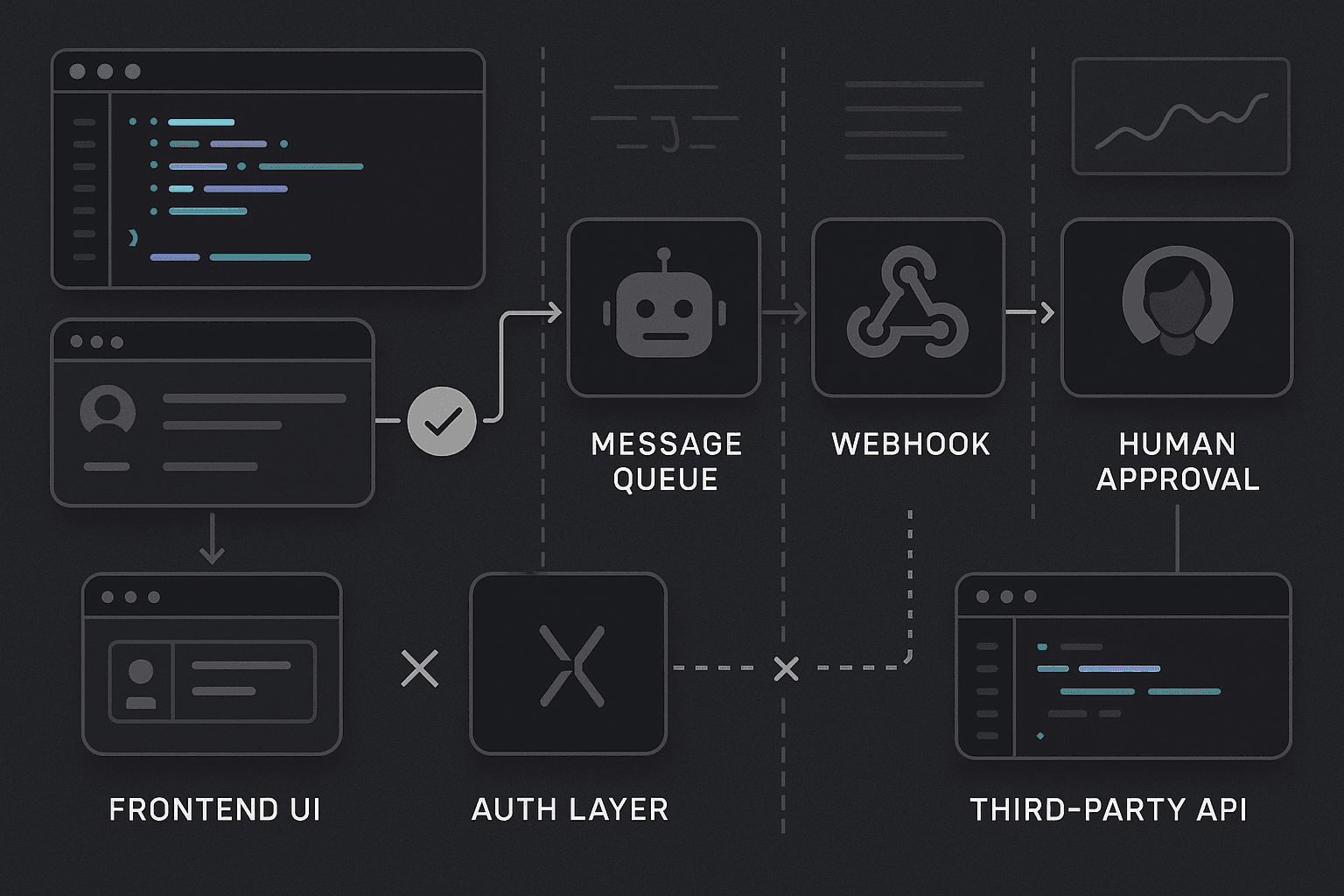
That is the real failure surface: the point where a workflow crosses a boundary between systems, roles, or asynchronous stages. Frontend to API. API to auth. Auth to job worker. Worker to webhook. Webhook to third-party API. System to human approver. One service to another team's contract. Those boundaries are where software silently stops honoring user intent.
This is not just a testing blind spot. It is a delivery blind spot. Modern CI/CD pipelines are optimized to verify isolated code paths, not workflow commitments. Traditional testing proves that components behave under controlled assumptions. Real users do not operate inside those assumptions. They traverse the full chain.
If you care about reliability, debugging, and developer productivity, this distinction matters. A system is not correct because a screen rendered the right state or an endpoint returned 200. A system is correct when the intended action actually propagates across the chain and reaches the real external consequence.
The Problem: Correct Locally, Broken at the Boundary
A lot of engineering teams still describe failures using implementation language:
- the queue consumer broke
- the webhook schema drifted
- auth middleware dropped context
- the UI sent stale data
- the approval state machine got stuck
That language is accurate, but it hides what the user experienced.
The user experience is simpler: I did the thing, and the thing did not happen.
Boundary failures are dangerous because the product often appears correct at each local checkpoint:
- The button click handler fired.
- The API request succeeded.
- The database row updated.
- The worker picked up the job.
- The external API acknowledged receipt.
- The UI showed an optimistic status.
Yet the workflow still fails because the guarantee between stages was never actually verified.
Agent-written changes amplify this because agents are excellent at satisfying explicit local constraints and weak at implicit cross-system intent unless you encode that intent directly. Given a task like “add approval flow for refunds,” an agent will usually wire up the obvious pieces. It may even read neighboring tests and imitate their patterns. But if your test suite only proves that the button renders, the controller returns 200, and the worker runs when manually invoked, the agent has no reason to discover that the actual product commitment is:
- A support rep clicks approve.
- The request carries the correct user and merchant identity.
- The server records an approval event with durable correlation.
- A job is enqueued with all required context.
- The worker calls the payment processor with the approved amount.
- A webhook updates the refund status.
- Finance receives the audit artifact.
- The support rep sees the final state only after the external action is confirmed.
That is the flow. That is what needs testing.
Most suites do not test that flow. They test fragments.
Why Green Tests Still Lie
The problem is not that unit tests are useless or that end-to-end tests do not matter. The problem is that teams mistake partial verification for workflow verification.
Unit tests prove functions, not commitments
Unit tests are good at checking deterministic behavior in isolation. That is valuable. They catch regressions quickly. They support refactoring. They improve debugging when failures are local and obvious.
But a unit test cannot tell you whether the user action propagated across a queue with the right identity, timing, retry semantics, and downstream side effects. The more mocks you use around a boundary, the easier it is to accidentally certify a fantasy.
An agent can write a passing unit test for this:
javascriptit('publishes refund job after approval', async () => { const queue = { publish: vi.fn().mockResolvedValue(true) }; const service = new RefundApprovalService({ queue }); await service.approve({ refundId: 'r_123', approvedBy: 'user_9', merchantId: 'm_77' }); expect(queue.publish).toHaveBeenCalledWith('refund.approved', { refundId: 'r_123', approvedBy: 'user_9', merchantId: 'm_77' }); });
Looks solid. But if the real queue publisher serializes merchant_id while the worker expects merchantId, this test proves nothing about production behavior. It only proves your mock accepted your expectations.
E2E tests often stop at the UI boundary
A surprising number of so-called end-to-end tests are really frontend integration tests with network stubbing. They launch the browser, click buttons, intercept requests, return fixtures, and assert UI state.
That is useful for frontend confidence. It is not the full workflow.
This Playwright test can pass while the real refund never happens:
javascriptimport { test, expect } from '@playwright/test'; test('support rep can approve a refund', async ({ page }) => { await page.route('**/api/refunds/r_123/approve', async route => { await route.fulfill({ status: 200, contentType: 'application/json', body: JSON.stringify({ status: 'processing' }) }); }); await page.goto('/refunds/r_123'); await page.getByRole('button', { name: 'Approve refund' }).click(); await expect(page.getByText('Refund approved')).toBeVisible(); await expect(page.getByText('Processing')).toBeVisible(); });
The UI works. The user journey in production may not.
The hidden assumption is that the backend, queue, worker, webhook, and processor will all behave consistently with the stub. That assumption is exactly where many failures live.
CI/CD validates mergeability, not reality
CI/CD systems are built around fast feedback and deterministic automation. That pushes teams toward checks that are cheap to run:
- linting
- type checks
- unit tests
- integration tests with local mocks
- short browser tests
- ephemeral environments with limited dependencies
None of that is wrong. But the result is predictable: pipelines tell you whether a change is internally consistent in a controlled environment, not whether it will survive real handoffs.
The deeper problem is that CI usually has no model of the workflow commitment. It knows a PR should compile, not that a user approval must lead to a real downstream settlement event within five minutes with an audit trail and retry visibility.
That gap creates false confidence. A green pipeline feels like proof. It is not proof. It is evidence of a narrow class of correctness.
QA cannot reliably catch boundary failures by exploration alone
Manual QA can find obvious broken flows, but boundary failures are often timing-sensitive, permission-sensitive, data-shape-sensitive, or environment-specific. They may require:
- the wrong role token
- a real webhook signature
- queue lag
- third-party sandbox behavior
- a delayed callback
- a mid-flow manual approval
- stale browser state
- duplicate delivery
These are difficult to explore systematically by hand, and almost impossible to cover thoroughly as product complexity grows.
If your workflow correctness depends on a human tester noticing that the final consequence never occurred three systems later, you do not have a reliable verification strategy.
The Core Insight: Test the Handoff, Not Just the Step
The right mental model is simple:
Every meaningful product action is a chain of commitments across boundaries.
Testing should assert not just that each step can execute, but that the output of one boundary becomes the valid, sufficient, and observable input to the next.
That means you need to verify propagation, not just local success.
For a real workflow, ask these questions:
- What user intent starts the chain?
- What evidence proves that intent crossed the first boundary correctly?
- What context must survive each hop?
- What external effect is the workflow promising?
- What observable signal confirms the effect happened?
- What should the user see before that confirmation versus after it?
- Where can timing, retries, auth, idempotency, and schema drift break the chain?
This shifts testing from “did this component respond correctly?” to “did the system uphold the user’s intended action across all boundaries?”
That is a harder question. It is also the one that matters.
Where Agent-Written Changes Commonly Break
AI-assisted development does not create boundary failures, but it makes them easier to introduce because the generated code often mirrors existing local patterns without understanding full workflow contracts.
1. Frontend event to backend contract
An agent updates a form or button handler and sends fields that look reasonable but do not preserve the backend’s real invariants.
Examples:
- sends display currency instead of settlement currency
- omits actor role or tenant scope
- renames a field to match frontend style
- fires duplicate events because optimistic state changed twice
- treats “accepted” as “completed”
2. Auth boundary
The request arrives, but key authorization context is lost or transformed.
Examples:
- background job runs under system identity without original actor metadata
- service-to-service token omits tenant claim
- admin UI path works in dev with broad permissions, fails in prod with scoped roles
- approval requires step-up auth that tests never modeled
3. Async queue boundary
The server says success after enqueue, but the enqueued message is insufficient, malformed, or semantically incomplete.
Examples:
- missing correlation IDs
- incompatible schema version
- serialized enum mismatch
- worker depends on data not included in payload
- race between DB commit and message publish
4. Webhook or callback boundary
The downstream system responds later, and your app assumes ideal callback behavior.
Examples:
- callback signature validation rejects sandbox payloads after a library change
- duplicate webhook creates inconsistent state
- out-of-order events regress status
- timeout path marks UI as failed while downstream action later succeeds
5. Third-party API boundary
Tests usually mock this boundary. Real systems rarely behave like mocks.
Examples:
- 202 Accepted instead of 200 OK
- partial success requiring polling
- stricter rate limits
- undocumented required field combinations
- idempotency keys handled differently in production
6. Human approval or operational handoff boundary
This is the most ignored category because it sits between software and process.
Examples:
- approval creates a task in the wrong queue
- required reviewer never notified
- status changes before legal/compliance signoff
- audit logs miss who approved what
- operators lack enough context to complete the handoff
These failures are not edge cases. They are normal consequences of workflows that cross boundaries.
A Better Verification Strategy: Assert End-to-End Propagation
You do not need to replace all existing testing. You need to add tests and observability that prove workflow propagation.
The key pattern is:
- Start from a real user-triggered action.
- Allow the chain to cross actual boundaries where possible.
- Assert on downstream evidence, not just upstream acknowledgment.
- Record correlation across steps so debugging is possible when the chain breaks.
Example architecture under test
Assume this flow:
- React UI sends refund approval request
- Node API validates and writes approval event
- API publishes job to queue
- Python worker calls payment processor
- Processor emits webhook
- API updates refund status
- Finance review task is created
A superficial test checks the UI response. A handoff-aware test verifies the full chain.
Code Example: Strengthening the Backend Contract
First, make the handoff explicit in code. Do not publish vague messages and hope downstream services infer missing context.
javascript// api/refunds/approveRefund.js import { randomUUID } from 'node:crypto'; export async function approveRefund(req, res, { db, queue }) { const correlationId = req.headers['x-correlation-id'] || randomUUID(); const actor = { userId: req.auth.userId, role: req.auth.role, tenantId: req.auth.tenantId, }; const { refundId } = req.params; const { amount, reason } = req.body; await db.transaction(async tx => { await tx.refundApprovals.insert({ refundId, amount, reason, approvedBy: actor.userId, tenantId: actor.tenantId, correlationId, status: 'approved_pending_execution', createdAt: new Date().toISOString(), }); await queue.publish('refund.approved.v2', { correlationId, refundId, tenantId: actor.tenantId, actor, amount, reason, approvedAt: new Date().toISOString(), schemaVersion: 2, }); }); res.status(202).json({ correlationId, status: 'approved_pending_execution', }); }
Several things matter here:
202reflects asynchronous reality better than200with fake completion semantics.correlationIdgives you a chain-wide handle for debugging.- actor and tenant context are preserved explicitly.
- the workflow state names the handoff honestly: pending execution, not completed.
This alone improves reliability because it reduces semantic ambiguity.
Code Example: Python Worker with Boundary Assertions
python# worker/refund_processor.py from dataclasses import dataclass @dataclass class RefundApprovedMessage: correlation_id: str refund_id: str tenant_id: str actor: dict amount: int reason: str schema_version: int def process_refund(message: RefundApprovedMessage, payment_api, db, task_service, logger): assert message.schema_version == 2, "unsupported schema version" assert message.tenant_id, "tenant_id is required" assert message.actor.get("userId"), "actor.userId is required" logger.info("processing refund", extra={ "correlation_id": message.correlation_id, "refund_id": message.refund_id, "tenant_id": message.tenant_id, }) response = payment_api.create_refund( refund_id=message.refund_id, tenant_id=message.tenant_id, amount=message.amount, idempotency_key=message.correlation_id, metadata={ "approved_by": message.actor["userId"], "reason": message.reason, }, ) db.refund_executions.insert({ "refund_id": message.refund_id, "correlation_id": message.correlation_id, "provider_ref": response["provider_ref"], "status": "submitted_to_processor", }) task_service.create_finance_review({ "refund_id": message.refund_id, "correlation_id": message.correlation_id, "provider_ref": response["provider_ref"], "tenant_id": message.tenant_id, })
This is still not enough by itself, but it demonstrates an important habit: enforce required cross-boundary context at the consumer. If a producer omitted critical fields, fail loudly with correlation, not silently with a half-broken downstream state.
Playwright Example: Verify the Full Workflow, Not the Toast
A realistic browser test should not stop after the click. It should verify that the system eventually reaches the real externally-confirmed state.
javascriptimport { test, expect } from '@playwright/test'; async function pollRefundStatus(request, refundId) { for (let i = 0; i < 20; i++) { const response = await request.get(`/api/test/refunds/${refundId}/status`); const body = await response.json(); if (body.status === 'completed') return body; await new Promise(r => setTimeout(r, 1000)); } throw new Error('Refund did not complete within timeout'); } test('refund approval propagates across queue, processor, webhook, and finance task', async ({ page, request }) => { const refundId = 'r_123'; await page.goto(`/refunds/${refundId}`); await page.getByRole('button', { name: 'Approve refund' }).click(); await expect(page.getByText('Approval submitted')).toBeVisible(); await expect(page.getByText('Pending execution')).toBeVisible(); const finalState = await pollRefundStatus(request, refundId); expect(finalState.processorStatus).toBe('succeeded'); expect(finalState.webhookReceived).toBe(true); expect(finalState.financeTaskCreated).toBe(true); expect(finalState.approvedBy).toBe('support-user-1'); await page.reload(); await expect(page.getByText('Completed')).toBeVisible(); });
This test assumes you expose a test-only status endpoint or equivalent harness in a pre-production environment. Some teams resist this because it feels impure. In practice, it is often the difference between verifying a workflow and pretending to.
CI/CD Example: Add a Boundary Verification Stage
Your pipeline should distinguish between local correctness and workflow correctness.
yamlname: ci on: pull_request: push: branches: [main] jobs: fast-checks: runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - uses: actions/setup-node@v4 with: node-version: 20 - run: npm ci - run: npm run lint - run: npm run typecheck - run: npm test browser-tests: runs-on: ubuntu-latest needs: fast-checks steps: - uses: actions/checkout@v4 - run: npm ci - run: npx playwright install --with-deps - run: npm run test:e2e boundary-verification: runs-on: ubuntu-latest needs: browser-tests steps: - uses: actions/checkout@v4 - run: docker compose up -d api worker queue webhook-mock finance-mock - run: ./scripts/wait-for-stack.sh - run: npm run test:workflow -- --grep "@boundary" - run: python scripts/assert_no_dead_letters.py - run: python scripts/assert_webhook_delivery.py - run: python scripts/assert_finance_tasks.py
This does not mean every PR needs a 45-minute gauntlet. It means your CI/CD system should contain at least one stage that verifies critical workflow handoffs with real infrastructure or high-fidelity substitutes.
For high-risk flows, that stage should be release-blocking.
Tools Comparison: What Each Layer Catches and Misses
Here is the practical tradeoff.
Unit tests
Good for:
- pure logic
- serializers
- validation rules
- state transitions
- fast debugging feedback
Misses:
- queue contracts
- auth propagation
- webhook reality
- third-party behavior
- multi-stage workflow commitments
Integration tests
Good for:
- database interactions
- API contracts inside one service
- message producer/consumer compatibility
- internal modules working together
Misses:
- full user intent propagation
- real browser behavior
- production auth topology
- external callback timing
Playwright/browser tests
Good for:
- real UI interactions
- accessibility regressions
- form behavior
- visible workflow states
- basic end-user confidence
Misses when heavily stubbed:
- real backend semantics
- queue and worker failures
- true async completion
- third-party edge behavior
Contract tests
Good for:
- schema compatibility across service boundaries
- catching drift earlier than full-system tests
- enforcing versioned expectations
Misses:
- sequencing issues
- retries and timing
- operational visibility
- human handoff correctness
Workflow or boundary verification tests
Good for:
- proving user intent reaches downstream consequence
- catching propagation failures
- validating async handoffs
- exposing false confidence from green UI/API tests
Costs:
- slower
- more environment complexity
- more harness work
- more careful test data management
That cost is justified for flows that affect revenue, trust, compliance, provisioning, billing, identity, or irreversible user actions.
Actionable Practices for Teams Shipping Agent-Written PRs
If you use AI-assisted development, adopt these practices aggressively.
1. Define workflow commitments explicitly
For every critical flow, write a short contract:
- trigger
- boundaries crossed
- required context at each hop
- final external consequence
- observable evidence of completion
- acceptable timeout/retry behavior
If this is not written down, your tests will drift toward local implementation details.
2. Treat “accepted” and “completed” as different states
A huge amount of user confusion and debugging waste comes from UI and APIs collapsing async acceptance into completion.
Use state names that reflect reality:
- submitted
- queued
- processing
- awaiting_callback
- completed
- failed_needs_retry
- failed_needs_manual_review
This reduces false confidence for both users and engineers.
3. Propagate correlation IDs everywhere
If a workflow crosses boundaries without a shared identifier, debugging becomes archaeology.
Correlation IDs should appear in:
- frontend-initiated requests
- queue messages
- worker logs
- webhook processing logs
- task creation records
- audit trails
This is not optional for serious systems.
4. Preserve actor and tenant context explicitly
Do not assume downstream systems can reconstruct identity correctly. Carry the minimal required context across boundaries, and validate it at the consumer.
Many production failures that look like “queue bugs” are actually authorization context bugs.
5. Add a small number of critical boundary tests
Do not try to fully system-test every path. Pick the flows where a broken handoff is expensive:
- payment approval
- account provisioning
- subscription changes
- invitation and access grants
- document signing
- refund execution
- compliance review submission
Build durable workflow tests for those first.
6. Avoid excessive stubbing in “end-to-end” tests
If you stub the exact boundaries where failures usually happen, your tests are performing confidence theater.
Use stubs selectively for non-critical dependencies, but keep critical handoffs real enough to expose contract, timing, and propagation issues.
7. Add dead-letter and retry assertions to test runs
A workflow test should fail not just when the UI looks wrong, but when hidden operational signals indicate a broken handoff.
Examples:
- dead-letter queue not empty
- webhook retry count exceeded
- missing finance task
- orphaned approval record with no execution record
- status stuck in intermediate state beyond threshold
These checks surface silent failures that normal UI assertions miss.
8. Require agent-generated changes to identify boundary impact
When an agent opens a PR, require structured notes such as:
- boundaries touched
- contracts changed
- async behavior changed
- auth context changed
- new observable signals added
- workflow tests updated
This forces both the agent and reviewer to reason beyond local code diffs.
9. Review for handoff semantics, not just code style
A senior review comment should often sound like this:
- What confirms the downstream action really happened?
- Where is tenant context preserved for the worker?
- What happens if the webhook arrives twice?
- Why does the UI say completed before processor confirmation?
- How do we debug this with one correlation ID?
That is much more valuable than arguing about helper function naming.
10. Make boundary observability part of the feature
Observability is not a post-incident concern. For async workflows, it is part of the product.
When you ship a feature crossing boundaries, also ship:
- correlation IDs
- structured logs
- event timelines
- stuck-state alerts
- queue depth dashboards
- webhook failure metrics
- audit entries for human approvals
Without these, debugging turns into distributed guesswork.
A Review Heuristic: Follow the Intent Chain
When reviewing a PR—especially an agent-written PR—trace one user action through the full chain.
Ask:
- What exact intent is the user expressing?
- How is that intent encoded in the first request?
- What context must survive each boundary?
- What evidence proves the next system accepted it meaningfully?
- What downstream effect are we actually promising?
- What confirms that effect occurred?
- What does the user see if the chain is delayed, duplicated, or broken?
- How do we debug one failed execution end to end?
If the PR cannot answer those questions, it is not production-ready, no matter how green the tests are.
Why This Matters More Now
AI increases output. That is already obvious. The less obvious consequence is that teams can now generate a lot more locally-correct code than they can deeply verify.
That changes the bottleneck.
The bottleneck is no longer writing the component, the endpoint, or even the test file. The bottleneck is ensuring that changes preserve real workflow commitments across boundaries.
If your testing strategy remains centered on isolated correctness, you will ship more regressions with more confidence and spend more time debugging failures that only appear when a real user traverses a real workflow.
This is why developer productivity cannot be measured by merged PR count or even by green CI/CD runs alone. Productive teams are the ones that reduce the distance between a user’s intended action and the system’s verified outcome.
That requires better testing, better observability, and better review discipline.
Conclusion
The most dangerous failures in modern software are often not inside components. They are between them.
A UI can render correctly. An endpoint can return success. A queue can accept a message. A worker can start. A webhook can eventually arrive. And the product can still fail the user because the handoff between those stages was never truly verified.
Agent-written changes make this more visible, not because agents are uniquely reckless, but because they expose a weakness that already existed: most teams test steps, not chains.
If you want reliability, stop treating green tests as proof that the workflow works. Start asking whether the intended action actually propagated across the boundaries that matter.
Test the handoff. Assert the downstream consequence. Preserve context across every hop. Make async state honest. Instrument the chain so debugging is possible.
That is how you reduce false confidence.
That is how you make CI/CD mean something.
And that is how you build systems that work for real users, not just for test runners.