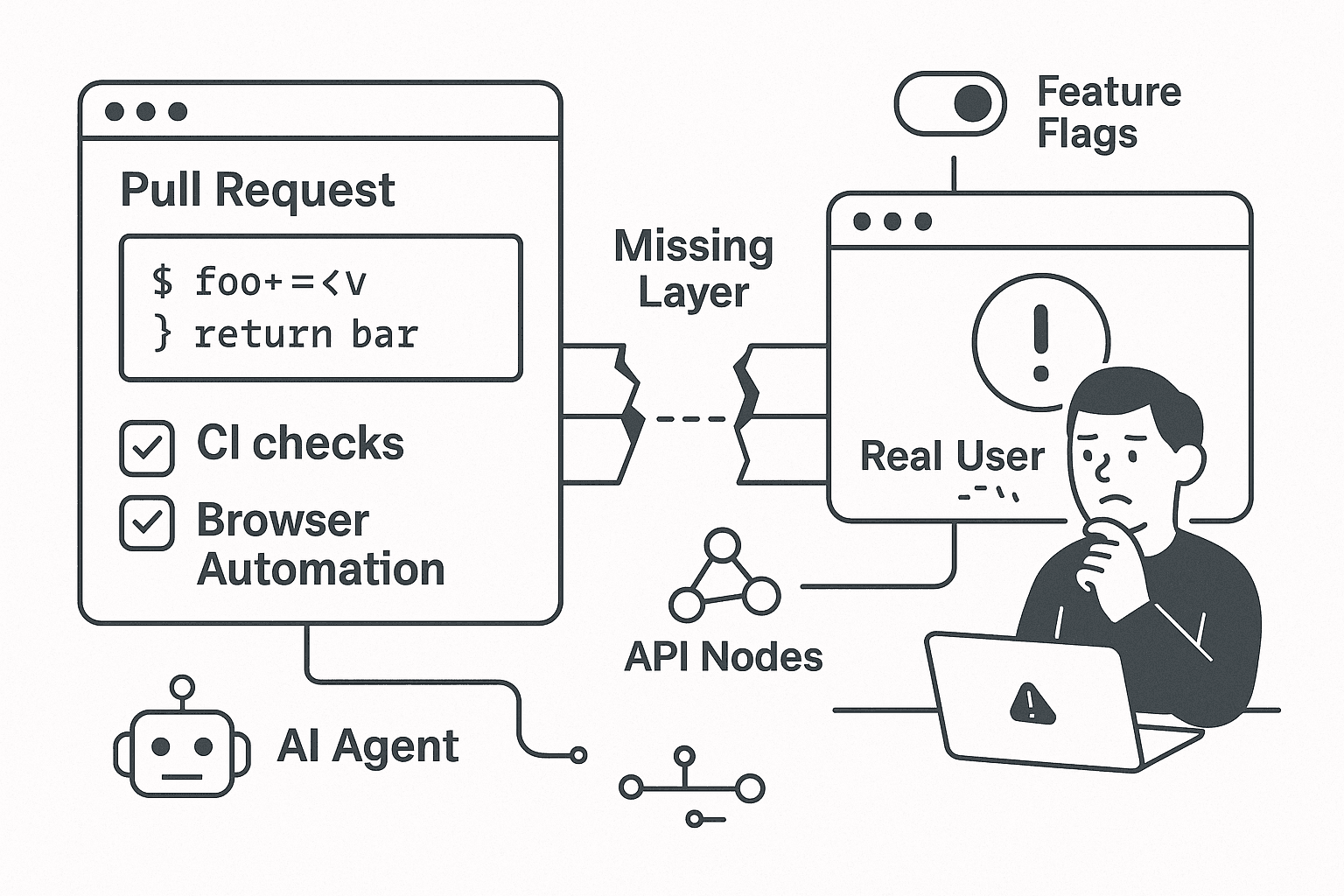
A pull request turns green. Unit tests pass. Snapshots match. Linting is clean. The deploy rolls out without a single infrastructure alert.
Then support gets a ticket: new users can sign up, but they never receive the onboarding email. Or they receive it, click the link, and land on a page hidden behind the wrong feature flag. Or the page loads, but the final “Create workspace” button stays disabled because a background job didn’t populate the expected state fast enough. Nothing “failed” in CI. Everything failed for the customer.
That gap is where a lot of modern teams are bleeding reliability.
It is getting worse, not better. AI now writes meaningful portions of production code. That increases output, but it also increases the volume of changes that no one fully simulates in their head. More code lands faster, often across layers: frontend, backend, jobs, glue code, auth flows, retries, webhooks, permissions. Traditional testing was already weak at validating these seams. Under high change velocity, it becomes dangerously easy to confuse “the PR passed” with “the product works.”
The problem is not that teams need more tests in the abstract. The problem is that most pipelines still verify code artifacts instead of user outcomes. They check functions, components, snapshots, contracts, and mocked integrations while missing the only question the business actually cares about: can a real user still complete a critical workflow after this change ships?
That missing layer sits between CI/CD and production reality. If you do not explicitly test it, your pipeline is mostly proving that your code is internally consistent, not that your product is operational.
The comforting lie of green CI
CI/CD has become a ritual of reassurance. A typical pull request triggers some combination of:
- linting
- type checks
- unit tests
- component tests
- API tests against mocks
- snapshot comparisons
- maybe a few end-to-end smoke tests
When all of those checks go green, teams treat that as evidence of safety. In practice, it is often evidence of local correctness under simplified assumptions.
That distinction matters.
A unit test might prove that createInvoice() returns the right object for a given input. A component test might prove that the billing form renders the right fields. A mocked API test might prove that when Stripe responds with a success payload, your code updates state correctly.
None of that proves a user can:
- sign in with the right permissions,
- add a payment method,
- create an invoice,
- trigger a background job,
- wait for a webhook,
- see UI state transition from pending to paid,
- and download the resulting receipt.
Yet that sequence is what your customer experiences.
This is the central failure of modern testing strategy: we verify pieces in isolation and assume the workflow survives composition.
It often does not.
The more your architecture depends on asynchronous systems, third-party services, event-driven updates, and conditional UI, the less confidence you should derive from isolated checks. Green CI is not worthless. It is just frequently over-interpreted.
Why AI-generated code makes this worse
The current wave of AI-assisted development amplifies an old weakness.
AI can produce plausible code quickly. It can refactor tests, add handlers, stitch together integrations, and update UI state management with impressive speed. But plausibility is not reliability. The model does not carry a durable mental simulation of your production workflow. It predicts useful code patterns. It does not deeply understand the downstream timing, dependency edges, or business-critical user journeys unless you force those constraints into verification.
That means teams are now merging larger and more numerous changes where:
- implementation looks correct,
- tests still pass,
- code review seems reasonable,
- but no one has actually exercised the end-to-end journey.
This is not an argument against AI. It is an argument against weak verification. If agents can produce changes faster than humans can reason through all side effects, then testing has to move up a level. You need checks that validate behavior the way customers experience it, not just the way developers decompose it.
Otherwise AI becomes a force multiplier for shipping unverified workflow regressions.
Why unit tests, QA, and traditional end-to-end tests still miss the real problem
Most teams know this in theory. They know unit tests are insufficient. They know manual QA is inconsistent. They know “we should probably have more E2E coverage.” And still the gap remains.
Why?
Because the issue is not simply test type. It is test scope and operating model.
Unit tests optimize for code paths, not journeys
Unit tests are excellent for local logic. They are fast, deterministic, cheap to run, and useful for debugging regressions in a small surface area. You absolutely want them.
But they are structurally bad at answering workflow questions.
A business journey crosses process boundaries, service boundaries, privilege boundaries, and time boundaries. Unit tests intentionally avoid all of that. They flatten reality into controllable inputs and outputs.
That is a feature, not a bug. It just means unit tests cannot be the final authority on product correctness.
QA happens too late and too selectively
Manual QA often catches the kinds of issues that automated checks miss, because humans actually try to complete real tasks. But QA has three chronic problems:
- it is expensive,
- it is inconsistent,
- and it usually runs after the system has already accumulated risk.
A QA person can validate a handful of flows in staging. They cannot exhaustively verify every critical journey on every pull request. And when release velocity increases, QA becomes a bottleneck or gets bypassed.
That leads to the worst of both worlds: teams assume QA will catch workflow regressions, but the process is not designed to provide that guarantee at PR granularity.
Most end-to-end tests are still too synthetic
Even when teams invest in Playwright or Cypress, the suite often drifts toward UI scripting rather than workflow verification.
You see tests like:
- click button
- assert modal appears
- fill form
- assert toast text equals “Saved”
Those are useful smoke checks. They are not enough.
Real failures tend to happen in the transitions:
- auth token refresh during a multi-step flow,
- delayed webhook processing,
- eventual consistency in search indexing,
- feature flag mismatch between frontend and backend,
- retries that duplicate side effects,
- role-based access changes after account creation,
- race conditions between optimistic UI and server reconciliation.
Most browser tests do not model these conditions. They stop at the first synchronous success indicator and declare victory.
Mocked integrations hide the exact things that break in production
Mocks are another source of false confidence. They are useful for speed and isolation, but they also erase the awkwardness of real systems:
- latency
- retries
- schema drift
- partial failures
- out-of-order events
- missing callbacks
- stale caches
- transient 403s from mis-scoped tokens
If your CI only sees the happy path represented by your mocks, then your pipeline is not verifying integration behavior. It is verifying your assumptions about integration behavior.
That is a big difference.
The missing layer: action-level verification
The answer is not “replace all tests with giant end-to-end scenarios.” That would be slow, brittle, and hard to debug.
The answer is to add a missing layer with a different purpose: action-level verification.
Action-level verification asks a simple question:
Given this pull request, can a critical user journey still complete in a realistic environment through a sequence of user and system actions?
Not “does this function return the expected value?”
Not “does this component render?”
Not “does the mocked API reply correctly?”
But: can the product perform the job the user came to do?
That means your CI should be able to verify workflows like:
- new user signs up, verifies email, creates workspace, invites teammate, and lands in an activated account
- admin connects Salesforce, sync job runs, leads appear, filtering works, and exports include synced records
- customer upgrades plan, payment succeeds, entitlements change, usage limits update, and gated UI unlocks
- developer creates API key, submits job, webhook fires, background processing completes, and result appears in dashboard
These are not implementation-level assertions. They are business journey assertions.
And they should run against an ephemeral environment wired closely enough to reality to expose the failures that matter.
What action-level verification looks like in practice
At a practical level, action-level verification usually has four parts:
- Ephemeral environment per PR
- Seeded but realistic dependencies
- Workflow runner that can execute user and system actions
- Assertions on outcomes, not internal implementation details
You do not need a perfect replica of production. But you do need enough real infrastructure to test the seams:
- real auth
- real database
- real background jobs
- real feature flag configuration
- real browser rendering
- sandboxed third-party APIs where possible
- controllable webhooks and async callbacks
The workflow runner can be plain Playwright, Playwright plus helper APIs, or an agentic executor that knows how to attempt a business journey and adapt to minor UI changes. The important part is not magic. The important part is what you verify.
A concrete example: the signup workflow that “passed” everything
Consider a SaaS app with the following onboarding path:
- User signs up.
- Verification email is queued.
- User clicks email link.
- Account gets marked verified.
- User creates first workspace.
- Trial entitlements are provisioned.
- Welcome checklist appears.
A pull request changes the event handling around account creation. Unit tests still pass. Component tests still pass. Mocked integration tests still pass.
But in production, a background worker now processes the provisioning event before the verification record is committed. The worker silently no-ops. The user reaches the app, but the workspace creation button stays disabled because entitlements were never attached.
That is exactly the kind of defect that isolated testing misses and workflow verification catches.
Here is what a Playwright-based test for that journey might look like.
tsimport { test, expect } from '@playwright/test'; async function fetchLatestEmailLink(email: string): Promise<string> { const res = await fetch(`${process.env.TEST_HELPER_URL}/emails/latest?to=${email}`); const data = await res.json(); return data.verificationLink; } async function waitForEntitlements(userEmail: string) { const deadline = Date.now() + 30_000; while (Date.now() < deadline) { const res = await fetch(`${process.env.TEST_HELPER_URL}/entitlements?email=${userEmail}`); const data = await res.json(); if (data.active === true && data.plan === 'trial') return; await new Promise(r => setTimeout(r, 1000)); } throw new Error('Entitlements were not provisioned within timeout'); } test('new user can complete onboarding workflow', async ({ page }) => { const email = `user-${Date.now()}@example.test`; const password = 'S3cureP@ssword!'; await page.goto(process.env.APP_URL!); await page.getByRole('link', { name: /sign up/i }).click(); await page.getByLabel(/email/i).fill(email); await page.getByLabel(/password/i).fill(password); await page.getByRole('button', { name: /create account/i }).click(); await expect(page.getByText(/check your email/i)).toBeVisible(); const verificationLink = await fetchLatestEmailLink(email); await page.goto(verificationLink); await expect(page.getByText(/email verified/i)).toBeVisible(); await waitForEntitlements(email); await page.getByLabel(/workspace name/i).fill('Acme Workspace'); await page.getByRole('button', { name: /create workspace/i }).click(); await expect(page.getByRole('heading', { name: /welcome/i })).toBeVisible(); await expect(page.getByText(/invite your team/i)).toBeVisible(); });
This test does a few important things differently from shallow E2E checks:
- it validates the actual journey,
- it crosses browser, email, backend, and async provisioning boundaries,
- it waits for a real business condition,
- and it asserts outcomes the user depends on.
It does not care whether the entitlement code lives in a queue worker, webhook handler, or transaction callback. It cares whether onboarding completes.
That is the right abstraction.
Adding system actions, not just browser clicks
The phrase “real user workflows” can be misleading because many workflows involve non-user actions too. A customer triggers one step, then the system performs several others.
A useful verifier needs to model both.
For example, say you have a document processing product:
- User uploads file.
- API stores metadata.
- Background job sends file to OCR vendor.
- Vendor posts callback.
- Parsed result is indexed.
- UI status moves from Processing to Complete.
- User opens extracted data.
A browser-only test can upload the file and stare at the screen. But workflow verification is stronger when it can also control and observe system actions.
For example, you might expose test-only helpers in ephemeral environments:
python# test_helpers.py from flask import Flask, request, jsonify from myapp.models import Job from myapp.workers import process_document_callback app = Flask(__name__) @app.post('/test/trigger-ocr-callback') def trigger_ocr_callback(): payload = request.json job_id = payload['job_id'] fake_vendor_payload = { 'job_id': job_id, 'status': 'completed', 'text': 'Invoice #1042 Total: $899.00' } process_document_callback(fake_vendor_payload) return jsonify({'ok': True}) @app.get('/test/job-status/<job_id>') def job_status(job_id): job = Job.query.get(job_id) return jsonify({ 'job_id': job.id, 'status': job.status, 'indexed': job.indexed, })
And then your Playwright test can combine user actions with system-level triggers:
tstest('uploaded document completes processing workflow', async ({ page, request }) => { await page.goto(process.env.APP_URL!); await page.getByLabel(/email/i).fill('ops@example.test'); await page.getByLabel(/password/i).fill('password'); await page.getByRole('button', { name: /sign in/i }).click(); await page.getByLabel(/upload file/i).setInputFiles('fixtures/invoice.pdf'); await page.getByRole('button', { name: /process document/i }).click(); const jobId = await page.locator('[data-job-id]').getAttribute('data-job-id'); expect(jobId).toBeTruthy(); await request.post(`${process.env.TEST_HELPER_URL}/trigger-ocr-callback`, { data: { job_id: jobId } }); await expect(page.getByText(/processing/i)).toBeVisible(); await page.reload(); await expect(page.getByText(/complete/i)).toBeVisible(); await page.getByRole('link', { name: /view extracted data/i }).click(); await expect(page.getByText(/invoice #1042/i)).toBeVisible(); });
This is still automated testing, but it is testing the workflow as an operational system, not as a collection of disconnected code units.
CI/CD should verify journeys before merge, not after blame assignment
If you agree that workflow correctness matters, the next question is where this belongs.
The answer is straightforward: before merge, in CI/CD, on the pull request, against an ephemeral environment built from that change.
Not just nightly.
Not just before a major release.
Not just in staging after three unrelated changes have piled up.
The point is to close the PR-to-product gap while the change is still attributable and cheap to fix.
A simplified GitHub Actions pipeline might look like this:
yamlname: pr-workflow-verification on: pull_request: branches: [main] jobs: build-and-verify: runs-on: ubuntu-latest timeout-minutes: 45 steps: - name: Checkout uses: actions/checkout@v4 - name: Setup Node uses: actions/setup-node@v4 with: node-version: 20 - name: Install dependencies run: npm ci - name: Start ephemeral stack run: docker compose -f docker-compose.ci.yml up -d --build - name: Wait for app readiness run: ./scripts/wait-for-stack.sh - name: Seed workflow fixtures run: npm run seed:ci - name: Run unit and integration tests run: npm test - name: Run critical workflow verification env: APP_URL: http://localhost:3000 TEST_HELPER_URL: http://localhost:4001/test run: npx playwright test tests/workflows - name: Collect logs on failure if: failure() run: | docker compose -f docker-compose.ci.yml logs > ci-logs.txt - name: Upload artifacts if: failure() uses: actions/upload-artifact@v4 with: name: workflow-debug-artifacts path: | ci-logs.txt playwright-report/ test-results/
This is not exotic. It is disciplined.
The important shift is that workflow verification becomes a merge gate for critical business journeys.
Where agents fit in
There is a lot of loose talk right now about using agents for testing. Most of it is either overhyped or vague. But there is one practical use case that is genuinely valuable: agents can execute realistic action sequences and adapt to minor interface variation while still being judged by deterministic business outcomes.
That matters because brittle test suites often fail for the wrong reason. A button label changes. A layout shifts. A selector breaks. Engineers stop trusting the signal.
A well-bounded agentic runner can help at the action layer by:
- navigating by intent rather than fragile selectors alone,
- handling multi-step flows with conditional branches,
- surfacing where the workflow broke in human-readable terms,
- and generating debugging traces tied to user goals.
But the agent should not be the source of truth. The source of truth remains explicit workflow success criteria.
For example:
- workspace exists,
- invitation email sent,
- job status reaches completed,
- report appears in dashboard,
- billing entitlement changes within timeout.
Think of agents as execution helpers and debugging assistants, not as magical replacement for test design.
Debugging gets easier when failures map to workflows
One underrated benefit of action-level verification is better debugging.
When a unit test fails, you learn a local invariant broke. That is useful, but often disconnected from business impact.
When a workflow verification fails, you get a direct answer to a much more operational question: which user journey is broken, and at what step?
That changes incident response and developer productivity.
Instead of saying:
- “One of the auth integration tests is flaky”
- “The dashboard spec timed out”
- “Webhook mocks need updating”
You can say:
- “New users can verify email but cannot create a workspace because trial entitlements were never provisioned.”
- “Customers can upgrade plans, but the feature-gated export action remains unavailable after payment.”
- “Document upload succeeds, but OCR callback never transitions the UI out of Processing.”
Those failure messages are actionable. They align with customer pain. They reduce time wasted translating test noise into product reality.
This is especially important in high-velocity environments where many changes are generated, reviewed, and merged quickly. Better debugging is not a nice-to-have. It is the only way to keep throughput from collapsing under investigation overhead.
Tool comparison: what each layer is good for
No single testing tool solves this. The right strategy is layered, with each layer answering a different question.
| Layer | Best for | Fast? | Realistic? | Typical blind spot |
|---|---|---|---|---|
| Lint/type checks | Syntax, static correctness, obvious misuse | Yes | No | Runtime behavior |
| Unit tests | Local logic, edge cases, regressions in pure code | Yes | Low | Cross-system workflows |
| Integration tests | Service boundaries, contracts, database behavior | Medium | Medium | Full user journeys and async orchestration |
| Component/UI tests | Rendering and interaction details | Medium | Low-Medium | Backend and state propagation |
| Mocked E2E | Basic UI flows in stable conditions | Medium | Medium | Real integrations, timing, async failures |
| Manual QA | Exploratory validation and weird edge cases | No | High | Coverage and repeatability |
| Action-level workflow verification | Critical business journeys in realistic PR environments | Medium | High | Requires disciplined scoping and infrastructure |
The mistake teams make is trying to stretch one layer to cover the responsibilities of another.
Unit tests are not bad because they do not validate signup emails. That is simply not their job.
Action-level verification is not bad because it is slower than unit tests. Its job is different. It is there to answer whether the product still works for the customer before you merge.
Actionable practices for teams that want to close the gap
This is where most articles get abstract. So here is the practical version.
1. Identify your top five revenue or retention-critical workflows
Do not start with “test everything.” Start with the flows that matter most if they break.
Examples:
- signup and activation
- checkout and upgrade
- invite teammate and accept invitation
- connect external integration and sync data
- submit job and receive result
If a workflow breaking would trigger support load, revenue loss, or failed onboarding, it belongs on the list.
2. Express workflows as outcome-based specs
Write them in terms of actions and business outcomes, not DOM trivia.
Bad:
- click
.btn-primary - assert
.toast-successcontains “Done”
Better:
- create account
- verify email
- create workspace
- confirm trial entitlements exist
- confirm user lands on active workspace dashboard
The implementation can change. The journey should still work.
3. Create test helpers for async and system boundaries
Most workflow failures live around jobs, emails, webhooks, feature flags, and external services. Give your CI a safe way to interact with those systems.
Examples:
- read outbound email from test mailbox
- trigger sandbox webhook callbacks
- inspect job state
- wait for search index completion
- override feature flags per environment
These helpers dramatically reduce brittleness while preserving realism where it matters.
4. Use ephemeral environments, not shared staging
Shared staging is a conflict generator. Data gets polluted. Flags drift. Other teams deploy unrelated changes. Failures become hard to attribute.
Ephemeral PR environments make workflow verification meaningful because the environment corresponds to the exact code under review.
That attribution is crucial for debugging and trust in CI/CD.
5. Gate merges on a small, high-signal workflow suite
Do not start with fifty journeys. Start with three to ten critical workflows that must never regress.
This suite should be:
- stable,
- understandable,
- tied to business importance,
- and treated as a first-class merge gate.
You can expand later. Early success depends on signal quality, not suite size.
6. Keep lower-level tests for diagnosis and speed
This is not a replacement for unit or integration testing. You still need them for fast feedback and easier root cause analysis.
The model is:
- lower layers prevent cheap mistakes,
- workflow verification prevents expensive illusions.
Both matter.
7. Capture artifacts that make failures debuggable
When workflow verification fails, save:
- browser trace
- screenshots/video
- application logs
- worker logs
- network traces
- state snapshots for jobs and flags
A failing workflow without observability is just another expensive mystery.
8. Review tests as product contracts
Critical workflow specs should be reviewed the way you review API contracts. They encode what the business promises users.
If your team changes onboarding semantics, billing entitlements, or integration sync behavior, the workflow spec should change deliberately. That creates alignment between product intent and verification.
Common objections, and why they usually fail
“This sounds slow”
Yes, slower than unit tests. Much cheaper than production regressions.
The right comparison is not against a 300ms unit test. It is against:
- a broken signup funnel for six hours,
- a billing flow that silently fails after merge,
- support escalations,
- rollback churn,
- and engineering time spent debugging under pressure.
You do not need hundreds of these checks. You need enough to cover your most important workflows.
“These tests will be flaky”
They will be flaky if you design them poorly, use shared environments, depend on fragile selectors, and ignore async determinism.
They can be stable if you:
- scope them to critical journeys,
- provide robust test helpers,
- wait on business conditions,
- run them in isolated environments,
- and treat them as engineering systems, not side projects.
Flakiness is not a law of nature. It is often a design failure.
“We already have staging”
Staging is useful. It is not enough.
A shared environment after merge does not protect the pull request decision. It only tells you that some bundle of changes may have broken something. By then attribution is worse, rollback cost is higher, and debugging is noisier.
Workflow verification belongs as close to the merge point as possible.
“Our app is too complex for this”
That is exactly when you need it.
Complexity is the reason local correctness stops being a meaningful safety signal. The more services, flags, async jobs, and integrations you have, the more dangerous it is to rely on code-path-level testing alone.
The real shift: stop testing code in isolation as a proxy for product correctness
The deeper point here is philosophical as much as technical.
For years, software teams have treated passing automated checks as a reasonable proxy for production safety. That was already shaky. In a world of AI-assisted development and accelerating change volume, it is becoming untenable.
If your pipeline only proves that individual parts behave under controlled conditions, then you do not have release confidence. You have a well-organized set of local proofs.
Users do not experience local proofs.
They experience journeys.
They experience whether they can sign up, pay, invite, upload, sync, search, export, and recover from edge states. They experience whether the system actually completes the job across all the seams your architecture introduced.
That is what your CI/CD pipeline should protect.
Conclusion
Your PR can pass and your product can still fail. That is not a rare edge case. It is a predictable outcome of testing strategies built around implementation details rather than user workflows.
Green checks are necessary, but they are not sufficient. Unit tests, integration tests, and even conventional end-to-end tests all have value. But none of them, by default, close the gap between “this change looks correct” and “this customer journey still works.”
Action-level verification is the missing layer.
It gives teams a way to validate critical business workflows in ephemeral PR environments before merge. It improves debugging by tying failures to user outcomes. It raises the quality bar without pretending that more low-level tests alone will solve the problem. And in teams where AI is generating more code than humans can fully reason about, it is quickly becoming non-optional.
The standard should be simple: do not just test whether code paths pass. Test whether the product still does the thing the user came to do.
That is the difference between a healthy CI pipeline and a dangerous illusion of safety.