A signup flow passed every unit test, every API contract test, and every CI check. The pull request was green. The deploy went out on schedule.
Then sales asked why new trial users weren’t showing up in the CRM.
The answer wasn’t in the signup endpoint. It wasn’t in the frontend validation logic either. The app accepted the form, created the user record, returned a 200, and redirected to the dashboard exactly as designed. But one field name had changed in a downstream event payload. The billing system still provisioned the account. The email provider still sent a welcome message. The CRM sync rejected the event silently because the schema no longer matched. No alert fired. No test failed. The workflow broke at the handoff.
That is what modern production failures look like.
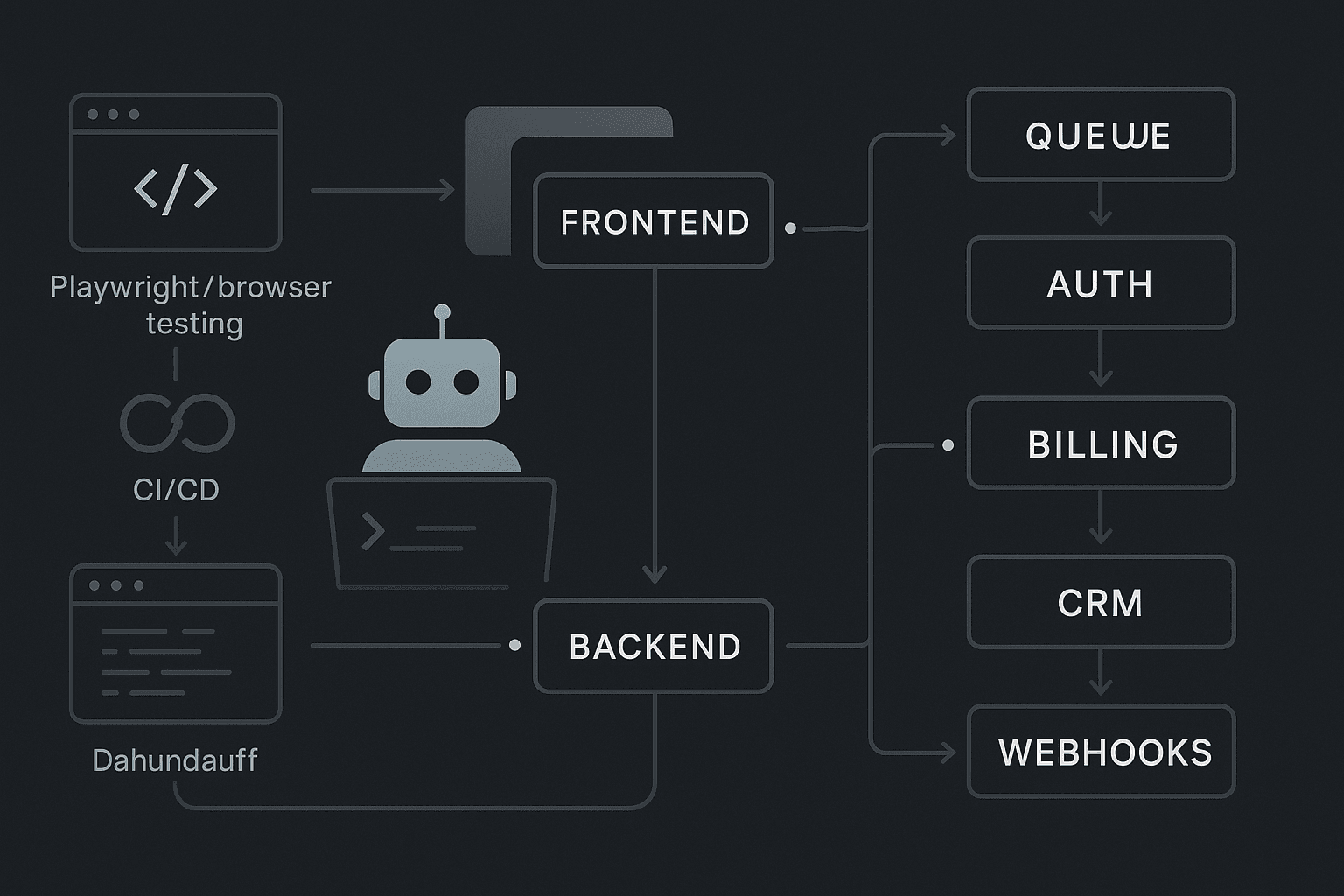
As AI agents generate more application code, this class of bug gets more common, not less. Agents are very good at making local changes that satisfy nearby tests. They are much worse at understanding the operational consequences of changing how data, state, and timing move across systems. A refactor that looks harmless inside a repo can break the exact point where your product depends on coordination: frontend to backend, app to queue, auth to billing, form submit to email, CRM, analytics, and webhook chains.
The uncomfortable truth is that most teams still test code paths while users depend on workflow paths. That gap is where “green” CI/CD pipelines create false confidence.
The new failure surface is the boundary, not the function
Traditional testing assumes the dangerous parts of the system live inside the code you directly control. So teams write unit tests for business logic, integration tests for endpoints, and UI tests for happy-path interactions. Those layers matter. But they mostly validate components in isolation.
Users do not experience your product in isolation.
A real workflow spans systems with different schemas, consistency models, retry behavior, authorization scopes, and operational guarantees. Consider a simple “start trial” action:
- User fills a frontend form.
- Browser sends a request to your backend.
- Backend creates a user and organization.
- Auth provider issues session state.
- Billing provider provisions a trial subscription.
- Event is published to a queue.
- Worker enriches the account.
- CRM contact is created.
- Welcome email is triggered.
- Analytics event is emitted.
- Internal Slack notification is sent.
From a customer perspective, that is one action. From your system’s perspective, it is a chain of handoffs.
Any one of these can fail in ways your API tests will never catch:
- The backend returns success before the queue publish actually commits.
- The worker retries and creates duplicate CRM records.
- The auth token lacks a scope required by billing in production only.
- The webhook consumer accepts malformed payloads in staging but rejects them behind stricter production validation.
- The frontend navigates away before an idempotency key is persisted.
- A field rename keeps the email flow working but breaks downstream segmentation.
- A background job succeeds after the user has already hit an error screen and retried, creating split state.
None of this is theoretical. These are standard distributed system failures, hidden behind otherwise healthy components.
The more systems you compose, the more your reliability depends on verifying the transitions between them.
Why agent-generated changes amplify handoff failures
AI-assisted development is not the root cause. It is a force multiplier.
Agents optimize for what they can see and measure. In most repositories, what they can see is local code, local tests, static types, and maybe some mocked integrations. That means they are naturally biased toward changes that preserve local correctness while accidentally weakening global behavior.
Here are a few common ways this happens.
1. Agents refactor semantics, not just syntax
An agent updates a serializer, extracts a shared utility, renames a field, or standardizes error handling. All of those can be reasonable changes. But in workflow-heavy systems, semantics matter more than formatting.
Changing customerId to customer_id might be harmless inside one service and catastrophic at a webhook boundary.
Changing the timing of when an event is emitted might still satisfy endpoint tests while breaking every consumer that assumed the record already existed.
2. Agents satisfy mocks that don’t behave like production
A test double often encodes an idealized integration:
- instant responses
- stable schema
- no retries
- no rate limits
- no partial failures
- no eventual consistency
An agent can make tests greener by aligning code more tightly to those mocks. In production, the real system is slower, stricter, or simply different.
3. Agents create broad changes with shallow understanding
A senior engineer might recognize that a billing callback and a CRM sync both depend on the same event envelope. An agent often won’t, unless those relationships are explicit and close by in code.
This is the core risk: larger surface area changes shipped faster into systems whose true contracts are social, implicit, or distributed across teams.
4. Agents increase deployment frequency without increasing verification depth
More code gets merged. More PRs are green. More changes reach production. If your testing strategy still centers on component-level validation, you just increased the rate at which boundary failures are introduced.
That is not an indictment of AI tools. It is a reminder that debugging and testing strategies must evolve with how code is produced.
Why current approaches fail: CI, unit tests, and manual QA
Most teams already have “good coverage” by conventional definitions. They still get burned by broken workflows because the common layers of validation stop too early.
CI/CD validates build integrity, not operational completion
A standard CI/CD pipeline answers questions like:
- Does the code compile?
- Do unit tests pass?
- Does the API return the expected response?
- Can the container build?
- Can we deploy safely?
Those are useful gates. They are not proof that a user action completes.
A pipeline can be perfectly green while a critical workflow silently stalls after the first hop.
Here is a familiar CI config that looks solid and still misses the real risk:
yamlname: ci on: pull_request: push: branches: [main] jobs: test: runs-on: ubuntu-latest services: postgres: image: postgres:15 env: POSTGRES_PASSWORD: postgres ports: - 5432:5432 redis: image: redis:7 ports: - 6379:6379 steps: - uses: actions/checkout@v4 - uses: actions/setup-node@v4 with: node-version: 20 - run: npm ci - run: npm run lint - run: npm run test - run: npm run test:integration - run: npm run build
This pipeline proves local integrity. It does not prove that “user submits form and account appears in billing, CRM, and email systems without duplication or silent loss.”
That difference matters more than ever.
Unit tests are precise but narrow
Unit tests are excellent for logic. They are terrible proxies for workflows.
If the bug lives in a transformation, retry policy, missing idempotency key, race condition, or downstream schema mismatch, your unit tests can all pass while customers are stuck in limbo.
A unit test for an event publisher might look like this:
javascriptimport { publishSignupEvent } from './events'; import { queue } from './queue'; jest.mock('./queue', () => ({ queue: { publish: jest.fn().mockResolvedValue({ ok: true }) } })); test('publishes signup event', async () => { await publishSignupEvent({ userId: 'u_123', email: 'user@example.com', plan: 'trial' }); expect(queue.publish).toHaveBeenCalledWith('user.signup', { userId: 'u_123', email: 'user@example.com', plan: 'trial' }); });
This is fine as far as it goes. But it tells you nothing about:
- whether the event survives serialization
- whether consumers expect
plan_typeinstead ofplan - whether the publish is transactional with the user record creation
- whether retries create duplicates
- whether downstream systems reject the payload
- whether the user sees success before the workflow actually completes
Unit tests can confirm that a function behaved correctly under assumptions. They cannot validate whether the assumptions hold across systems.
Manual QA checks interfaces, not system truth
Manual QA has a place, especially for exploratory work. But workflow failures are often asynchronous, conditional, and delayed.
The QA tester sees:
- form submits successfully
- UI redirects correctly
- success toast appears
- dashboard loads
What they don’t necessarily see:
- lead missing in the CRM 3 minutes later
- duplicate charge after a retry storm
- webhook delivery dead-lettered
- account provisioned but email never sent
- billing trial created without the entitlement row your app needs
Human testing is not built to continuously verify invisible handoffs. That is an automation problem.
The core insight: stop testing requests, start testing actions
The right abstraction is not “did endpoint X return 200?”
It is “did the user action complete all required handoffs?”
That shift sounds small, but it changes everything.
A request is local. An action is distributed.
An action-level test starts at the interface the user or operator touches, triggers the real workflow, and verifies the side effects at each boundary that matter. It treats success as operational completion, not merely application acknowledgment.
This is what modern reliability work needs to look like:
- Start from a user action.
- Observe every critical handoff.
- Verify completion across systems.
- Detect stalls, drops, duplicates, and misordered side effects.
- Run under production-like timing and auth assumptions.
If you do that, you stop being fooled by green builds that only validate the first 20% of reality.
What action-level verification looks like in practice
You do not need to simulate the entire internet. You need to define the workflows that matter most and prove the critical handoffs complete.
For a signup flow, your verification might assert:
- frontend form submission succeeds
- backend user row exists
- organization row exists
- billing trial exists with expected plan
- queue event is emitted exactly once
- worker processes event successfully
- CRM contact exists with correct identifiers
- welcome email trigger is recorded
- analytics event appears once
That is the difference between testing your app and testing your business process.
Example: a brittle implementation that passes local tests
Here is a simplified Node.js handler that looks reasonable but can fail at the workflow boundary.
javascriptapp.post('/api/signup', async (req, res) => { const { email, companyName, plan } = req.body; const user = await db.user.create({ data: { email } }); const org = await db.organization.create({ data: { name: companyName, ownerId: user.id } }); await billing.createTrial({ email, externalCustomerId: org.id, plan }); queue.publish('user.signup', { userId: user.id, orgId: org.id, email, plan }); res.status(200).json({ ok: true, userId: user.id, orgId: org.id }); });
Problems:
queue.publishis not awaited.- There is no transactional outbox or handoff guarantee.
- Billing succeeds before event publication is confirmed.
- A client can retry and create duplicate downstream state.
- Response success implies workflow success even though only part of it completed.
A local integration test may still pass every time.
Better: explicit handoff guarantees and idempotency
A more resilient version separates acknowledgment from completion and makes the workflow observable.
javascriptimport { randomUUID } from 'node:crypto'; app.post('/api/signup', async (req, res) => { const { email, companyName, plan } = req.body; const idempotencyKey = req.header('Idempotency-Key') || randomUUID(); const existing = await db.signupRequest.findUnique({ where: { idempotencyKey } }); if (existing) { return res.status(202).json({ requestId: existing.id, status: existing.status }); } const signupRequest = await db.$transaction(async (tx) => { const request = await tx.signupRequest.create({ data: { idempotencyKey, email, companyName, plan, status: 'pending' } }); await tx.outbox.create({ data: { topic: 'signup.requested', aggregateId: request.id, payload: JSON.stringify({ requestId: request.id, email, companyName, plan }) } }); return request; }); res.status(202).json({ requestId: signupRequest.id, status: 'pending' }); });
A worker can then process the outbox reliably and update workflow status as each boundary completes.
pythonasync def process_signup_requested(event, db, billing, crm, emailer): request_id = event["requestId"] request = await db.signup_request.get(request_id) if request.status == "completed": return user = await db.user.upsert_by_email(request.email) org = await db.organization.upsert_by_request(request_id, request.company_name, user.id) billing_result = await billing.ensure_trial( external_customer_id=org.id, email=request.email, plan=request.plan, idempotency_key=f"signup:{request_id}:billing" ) await crm.upsert_contact( external_id=user.id, email=request.email, company=request.company_name ) await emailer.send_welcome( to=request.email, template="trial_welcome", metadata={"request_id": request_id} ) await db.signup_request.update( request_id, { "status": "completed", "user_id": user.id, "org_id": org.id, "billing_customer_id": billing_result["customer_id"] } )
This does not magically remove failures. It makes them controllable, retryable, and testable.
Testing the workflow with Playwright plus backend assertions
UI testing alone is not enough, but UI initiation is often the correct entry point because that matches the user action.
With Playwright, you can trigger the workflow from the browser, then verify the downstream state through internal admin endpoints, database checks, or test-only observability hooks.
javascriptimport { test, expect } from '@playwright/test'; test('signup completes all critical handoffs', async ({ page, request }) => { const email = `test-${Date.now()}@example.com`; await page.goto('/signup'); await page.fill('[name="companyName"]', 'Boundary Test Inc'); await page.fill('[name="email"]', email); await page.selectOption('[name="plan"]', 'trial'); await page.click('button[type="submit"]'); await expect(page.getByText('Check your email to continue')).toBeVisible(); await expect.poll(async () => { const res = await request.get(`/test-api/workflows/signup-status?email=${email}`); return res.json(); }, { timeout: 30000, intervals: [500, 1000, 2000] }).toMatchObject({ appUserCreated: true, organizationCreated: true, billingTrialCreated: true, crmContactCreated: true, welcomeEmailTriggered: true, status: 'completed' }); });
That test is much closer to what the business actually needs.
Critically, it verifies the handoffs instead of stopping at the first success screen.
Add production-like failure modes to your tests
If your verification only checks the happy path, you are still under-testing boundaries.
You need scenarios for:
- delayed downstream systems
- duplicate deliveries
- partial completion
- auth token expiry
- webhook retry and reorder
- queue processing lag
- provider validation drift
For example, test that retry behavior does not create duplicate billing state:
javascripttest('signup is idempotent across client retry', async ({ request }) => { const email = `retry-${Date.now()}@example.com`; const key = `idem-${Date.now()}`; const payload = { email, companyName: 'Retry Co', plan: 'trial' }; const [r1, r2] = await Promise.all([ request.post('/api/signup', { headers: { 'Idempotency-Key': key }, data: payload }), request.post('/api/signup', { headers: { 'Idempotency-Key': key }, data: payload }) ]); expect([202, 202]).toContain(r1.status()); expect([202, 202]).toContain(r2.status()); await expect.poll(async () => { const res = await request.get(`/test-api/workflows/signup-status?email=${email}`); return res.json(); }).toMatchObject({ billingTrialCount: 1, crmContactCount: 1, status: 'completed' }); });
This kind of test catches a whole class of workflow bugs that API contract tests miss completely.
CI/CD should run workflow verification, not just code verification
If workflow boundaries are the failure surface, your CI/CD pipeline needs a stage that explicitly validates them.
That does not mean every PR must spin up every real external dependency. It means you need a strategy for meaningful workflow verification at the right layers.
A practical model looks like this:
- PR checks: unit, integration, schema compatibility, critical workflow smoke tests against controlled environments
- main branch: broader end-to-end workflow suite
- pre-release or canary: production-like verification against real integrations or high-fidelity sandboxes
- post-deploy: synthetic action-level checks continuously exercising critical workflows
Here is an example GitHub Actions workflow with a dedicated workflow-verification job:
yamlname: workflow-verification on: pull_request: push: branches: [main] jobs: app-tests: runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - uses: actions/setup-node@v4 with: node-version: 20 - run: npm ci - run: npm run test - run: npm run test:integration workflow-smoke: needs: app-tests runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - uses: actions/setup-node@v4 with: node-version: 20 - run: npm ci - run: docker compose up -d - run: npm run db:migrate - run: npm run test:workflow env: BILLING_BASE_URL: http://localhost:4010 CRM_BASE_URL: http://localhost:4020 EMAIL_BASE_URL: http://localhost:4030 canary-workflows: if: github.ref == 'refs/heads/main' needs: workflow-smoke runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - uses: actions/setup-node@v4 with: node-version: 20 - run: npm ci - run: npm run test:workflow:canary env: APP_BASE_URL: ${{ secrets.CANARY_APP_BASE_URL }} BILLING_SANDBOX_KEY: ${{ secrets.BILLING_SANDBOX_KEY }} CRM_SANDBOX_KEY: ${{ secrets.CRM_SANDBOX_KEY }}
This is closer to reality because it acknowledges that developer productivity is not just about writing code faster. It is about reducing the time between change and reliable confidence.
What to verify at each boundary
Not every integration deserves the same investment. Focus on workflows where failure has customer or revenue impact.
For each boundary, verify four things:
1. Delivery
Did the handoff happen at all?
Examples:
- event published
- webhook sent
- job enqueued
- API call made
2. Acceptance
Did the receiving system accept it?
Examples:
- 2xx from provider is real, not just connection success
- payload validated
- auth scopes accepted
- consumer deserialized without dropping fields
3. Effect
Did the intended side effect occur?
Examples:
- customer created in billing
- contact visible in CRM
- entitlement row created
- email trigger recorded
4. Uniqueness and ordering
Did it happen once, in the expected sequence?
Examples:
- no duplicate subscriptions
- no duplicate emails
- no worker processing before source row committed
- no stale webhook overwriting newer state
If your test suite does not answer these questions for critical workflows, it is not actually validating reliability.
Tools comparison: what each layer is good for
No single tool solves this. The point is to use each one for the right job.
| Tool/Approach | Good for | Weak at |
|---|---|---|
| Unit tests | business logic, edge cases, transformations | cross-system behavior, timing, retries |
| API integration tests | endpoint contracts, database effects | downstream async workflows, external side effects |
| Playwright/Cypress UI tests | user initiation, visible UX, browser state | invisible backend handoffs unless extended |
| Contract tests | schema compatibility between known producers/consumers | operational completion, retries, ordering |
| Mock servers | deterministic local testing, failure injection | fidelity to real production integrations |
| Sandbox integration tests | realistic provider behavior | cost, slowness, environment drift |
| Synthetic production checks | real operational confidence | narrower debugging signal, needs guardrails |
| Observability/tracing | debugging workflow failures in production | not a substitute for pre-deploy verification |
The mistake is expecting any one of these to carry the full load.
The right stack combines them around critical actions.
Actionable practices for teams shipping agent-assisted code
This is the part that matters. If you want fewer boundary failures, make the workflow explicit in both architecture and testing.
1. Define your critical user workflows
List the actions that actually matter to the business:
- signup and onboarding
- upgrade and billing change
- password reset
- invite teammate
- import data
- submit lead form
- cancel subscription
- generate report and notify user
If a failure would lose revenue, break trust, or create operational cleanup, it needs action-level verification.
2. Model handoffs as first-class states
Do not compress a distributed workflow into a single “success” response.
Track states like:
- requested
- accepted
- processing
- billing_completed
- crm_completed
- email_completed
- completed
- failed
This makes debugging easier and enables testing against real workflow progress rather than guessing from logs.
3. Add idempotency everywhere retries can happen
At the boundary, retries are normal. Networks fail. browsers retry. workers restart. webhooks redeliver.
If your workflow cannot safely repeat, it will eventually corrupt state.
Use:
- idempotency keys on external writes
- dedupe keys on events
- upserts on downstream records
- monotonic version checks where ordering matters
4. Prefer outbox and inbox patterns over best-effort async calls
If you create state and emit an event, make the handoff durable.
Best-effort publish after commit is where workflows disappear.
Transactional outbox patterns are not glamorous, but they close one of the most common reliability gaps in modern systems.
5. Build test-only workflow status endpoints or fixtures
Engineers often avoid workflow testing because downstream verification feels hard. Make it easier.
Expose internal test helpers that answer questions like:
- has the CRM sync completed?
- how many billing subscriptions exist for this request?
- did the welcome email trigger fire?
- what state is the workflow in now?
You are not cheating. You are making invisible system behavior observable enough to test.
6. Run a small set of high-value workflow tests on every meaningful change
Do not start with fifty brittle end-to-end scenarios. Start with five workflows that matter.
A few high-signal action tests catch more production-risking bugs than a mountain of component checks pretending to represent reality.
7. Continuously exercise workflows after deploy
Pre-merge checks are not enough. Real integrations drift. Auth scopes change. provider behavior changes. Queues back up.
Run synthetic workflow checks in staging and production-like environments. Alert on incomplete actions, not just service uptime.
A homepage returning 200 tells you nothing about whether customers can actually onboard.
8. Use tracing to connect the workflow for debugging
When a handoff fails, developers need to see the chain quickly.
Correlate:
- browser/session request id
- app request id
- outbox event id
- worker execution id
- provider request id
- webhook delivery id
Without this, debugging turns into log archaeology across six systems. With it, you can answer where the workflow stalled in minutes instead of hours.
9. Review agent-generated changes for boundary semantics
When AI proposes changes, reviewers should ask:
- Did any payload shape change?
- Did any event timing change?
- Did any retry behavior change?
- Did any field rename cross a service boundary?
- Did any mock hide a real integration requirement?
- Is idempotency still preserved?
This is a better review checklist than just asking whether the code is clean.
10. Measure workflow completion as a product health metric
Track metrics like:
- signup completion rate across all downstream systems
- median and p95 time to full workflow completion
- duplicate side-effect rate
- dead-letter rate by workflow type
- partial completion rate
If you do not measure handoff completion, you will keep optimizing the wrong thing.
A better mental model for modern testing
Old model: confidence comes from proving each component works.
Better model: confidence comes from proving important actions complete under realistic conditions.
The old model was always incomplete, but it was tolerable when systems were smaller, changes were slower, and fewer integrations were involved.
That world is gone.
Now we have:
- more services
- more vendors
- more async behavior
- more generated code
- more deploys
- more hidden contracts between systems
In that environment, workflow boundaries are where reliability is won or lost.
Testing has to follow that reality.
Conclusion
Your tests may cover the API. Your CI/CD pipeline may be green. Your agent may have produced perfectly plausible code.
None of that proves the user action completed.
The real failure surface in modern software is the handoff between systems: where one component says “done” and another quietly disagrees. That is where signups stall, charges duplicate, emails vanish, CRM records drift, and operators learn too late that a workflow only partially existed.
If AI-assisted development is increasing the speed and volume of change, then the answer is not more faith in isolated tests. It is better testing aimed at the actual risk.
Test actions, not just endpoints. Verify handoffs, not just handlers. Measure completion, not just response codes.
That is what real reliability looks like now. And it is the only kind of confidence that survives contact with production.